
“暗云”肆虐 途隆云成功抵御10小时900G海量攻击

2017年6月10日上午,腾讯电脑管家称已检测到“暗云Ⅲ”病毒大规模传播,感染用户达数百万且已被黑客远程控制变成“肉鸡”(僵尸电脑)向云服务提供商发起DDoS攻击。
在此次“暗云”风暴掀起的史无前例的肆虐中,国内多家云服务商受到严重冲击,而截至到目前,途隆云已成功抵御所有“暗云”攻击,作为重灾区的游戏行业此次攻击中影响明显,而在途隆云平台上所有游戏用户均安然无恙,业务未受任何影响。
早在2017年5月27日,途隆云已监测到来自全国节点的大流量攻击,攻击活动源地址具有罕见的广泛性分布特点,在全国所有省市骨干网络上都有活动,据途隆安全态势感知系统分析监测,攻击源所在城市主要为:广州、北京、杭州、西安、上海、深圳、嘉兴、南充、南昌、成都等地区,攻击源全部为被黑客控制的“肉鸡”。
其中在2017年5月28日 8:14:10, 途隆云高防BGP数据中心遭受了黑客组织史无前例的激烈的定向攻击,攻击一直持续到16:31:51,历时8小时,攻击流量达到650G,其中电信线路受到的攻击为488G,联通线路受到的攻击为166G。攻击强度达到每秒3亿次连接,本次攻击未对途隆云安全业务造成任何影响,途隆云服务器上的用户业务安然无恙。(超大规模网络攻击时代已来!途隆云遭受650G DDoS攻击)
而就在上周,暗云风暴再掀高潮,6月7日 12:49分起至22:10分,途隆云再次遭到来自全国范围“肉鸡”的超大规模DDoS攻击。而在这场总流量900G,攻击时长达10个小时的对抗中,途隆云成功抵御DDoS流量攻击534次,累积防护攻击达63T。其中两轮针对游戏用户的轮询攻击均被成功击退。

扫段攻击特征图
途隆云安全抵御峰值总流量达511165.53+390391.84=901557.37≈ 901Gbps
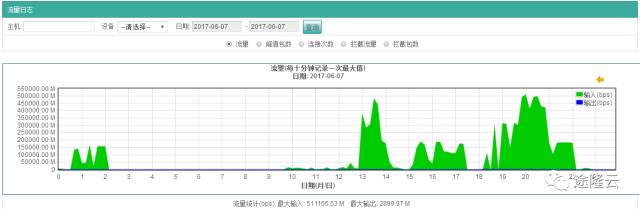
电信峰值流量图
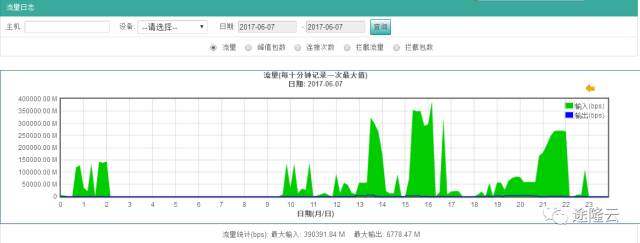
联通峰值流量图
途隆云安全成功抵御攻击:211+323=534次
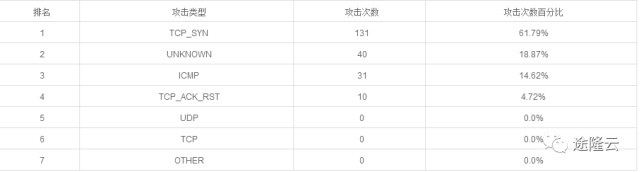
电信业务攻击次数图

联通业务攻击次数图
据途隆云安全实验室监测,此次攻击与2017年5月26日的全国范围DDoS攻击为同一黑客组织,攻击形式主要以SYN洪水攻击为主,在整个攻击中占比达61.79%,规模远超过以往,而且是采取扫段攻击方式。扫段攻击的主要特点是针对某几个IP进行大流量攻击,对该IP段其余的地址采取定量轮询攻击,该攻击手法主要是应对数据中心的黑洞策略,如果云服务商不具备强大的单点抗攻击能力,会导致整个IP段被黑洞,对用户影响极大,后果非常严重。
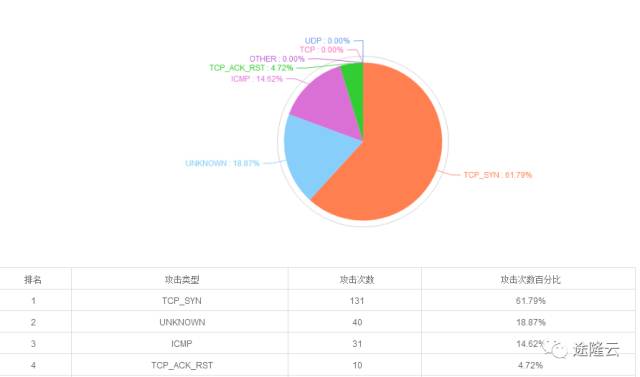
攻击类型比例图
途隆云安全累积防护攻击达:33991.35481+29079.38412=63070.73893Gbps

电信侧累计防护带宽图

联通侧累计防护带宽图
途隆云郑重提醒广大用户:网络攻击形势异常严峻,大流量攻击事件必然会呈现猛增趋势,抗击超大规模攻击已成为企业安全防护的重中之重,如不能有效防护,损失难以估算。
在目前的形势下,“暗云”风暴并非个例,抗DDoS攻击厂商面临更加严峻的挑战,截止到目前为止,单点攻击最高已经达到901G,目前业内大部分厂商单点防御能力在400G左右,途隆云仍以1.3T的单点抗D能力居行业之首。企业用户应选择具备T级以上防护实力的云服务商,提前做好防护预案,方可安枕无虞。
此外,近期途隆云还将推出“肉鸡”检测工具,让用户电脑及时进行自我体检,进一步在源头截断黑客的组织的网络攻击布局,并愿携手行业合作伙伴,共同建立协同联动的云安全体系,为行业的健康发展贡献一己之力。
好文章,需要你的鼓励


人工智能使用大揭秘:OpenRouter公司百万亿规模数据分析报告
这项由OpenRouter公司团队和Andreessen Horowitz(a16z)投资机构联合开展的研究,于2025年12月发表。

让AI看图功能瘦身90%:希腊塞萨洛尼基大学发现图像修复“中奖彩票“神经网络
希腊塞萨洛尼基大学研究团队开发出MIR-L算法,通过"彩票假说"发现大型图像修复网络中的关键子网络。该算法采用迭代剪枝策略,将网络参数减少90%的同时保持甚至提升修复性能。MIR-L能同时处理去雨、去雾、降噪等多种图片问题,为资源受限设备的实时图像处理提供了高效解决方案,具有重要的实用价值和环保意义。

通用汽车推出原生Apple Music应用并支持空间音频
通用汽车宣布为部分2025款及更新凯迪拉克和雪佛兰车型推出原生Apple Music应用。凯迪拉克车型还将支持杜比全景声空间音频技术,打造沉浸式三维音效体验。作为OnStar Basics服务的一部分,通用汽车为所有2025款及更新车型提供八年免费音频流媒体服务,支持Spotify和Apple Music等应用。该应用将通过OTA更新自动安装到支持的车辆中。

卡内基梅隆大学提出DistCA:让AI训练告别“木桶效应“的神奇技术
卡内基梅隆大学团队提出DistCA技术,通过分离AI模型中的注意力计算解决长文本训练负载不平衡问题。该技术将计算密集的注意力任务独立调度到专门服务器,配合乒乓执行机制隐藏通信开销,在512个GPU的大规模实验中实现35%的训练加速,为高效长文本AI模型训练提供了新方案。

