
境外APT-C1组织攻击我国某互金平台
至顶网安全频道 01月11日 综合消息: 2018/01/11,绿盟科技发布报告《互金大盗背后的高级威胁组织APT-C1》。报告首次发现并命名了境外APT-C1组织,他们利用“互金大盗”恶意软件攻击我国某互金平台,导致平台数字资产被窃,损失高达150万美元。
APT-C1组织攻击我国互金平台
在整个攻击事件中,攻击者在战术、技术及过程三个方面(TTP)表现出高级威胁的特征,包括高度目的性、高度隐蔽性、高度危害性、高度复合性、目标实体化及攻击非对称化,在国际网络安全领域通常使用这些特征,来标识及识别高级持续性威胁(APT)攻击,同时由于其攻击主要针对我国互联网金融领域,因此将其命名为APT-C1。

进一步分析显示,APT-C1组织开发的“互金大盗”,从2015 年5 月开始,逐步聚焦到互联网金融领域,并不断收集捕获包括比特币、莱特币、以太坊、比特币现金在内的12 种数字资产、22 个第三方钱包、8 个交易平台的敏感文件。当发现入侵目标后(我国某互联网金融交易平台),即展开持续进攻,直至进入该平台窃取凭证后,转移150万美元的数字资产。
APT-C1的进攻战术隐蔽且危害性大
与其它高级威胁攻击不同,APT-C1组织清楚的认识到,在面对互联网金融这样的大资金交易平台时,如果采用大规模感染且自动化攻击的形式,容易引起警觉很难奏效。故而攻击者长期活跃在互金社区解答用户问题,尤其关注互金平台管理员的痛点,然后有针对性的设置“诱饵”,将“互金大盗”恶意软件捆绑到管理员工具上,并在有限范围内扩散。一旦有“鱼”上钩,就展开有针对性的攻击。
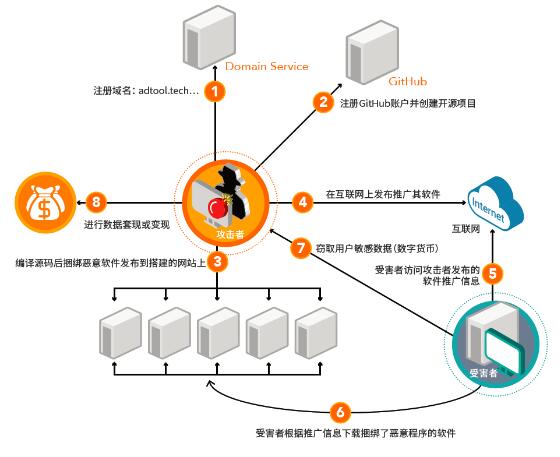
在目前发现的单个案例中,已经成功转移了数字资产,在更大范围的相关托管机构还有可能发生更为严重的“币池”资产转移,一旦投资者托管的钱包和密钥被窃取,将导致大规模数字资产失窃。目前,绿盟威胁情报中心捕获到“互金大盗”恶意软件的29 个样本,相关域名5 个,而这些样本在国际通行的60个防病毒引擎中,只有两个能察觉到。
有效应对互金大盗的攻击
APT-C1组织的攻击较为复杂,但针对其目前使用的“互金大盗”恶意软件,绿盟威胁情报中心NTI已经具备了防御能力,并持续追踪相关威胁情报,客户登录该平台即可实时查询相关信息。在NTI支持下,还可以利用绿盟入侵防御系统NIPS 进行网络边界防护,并利用绿盟威胁分析系统TAC进行内部网络的检测。
好文章,需要你的鼓励


无需验证师:如何让大型语言模型在没有答案检查者的情况下进行更好的推理
这项研究提出了"VeriFree"——一种不需要验证器的方法,可以增强大型语言模型(LLM)的通用推理能力。传统方法如DeepSeek-R1-Zero需要验证答案正确性,限制了其在数学和编程以外领域的应用。VeriFree巧妙地计算正确答案在模型生成的推理过程后出现的概率,作为评估和训练信号。实验表明,这种方法不仅能匹配甚至超越基于验证器的方法,还大幅降低了计算资源需求,同时消除了"奖励黑客"问题。这一突破将有助于开发出在化学、医疗、法律等广泛领域具有更强推理能力的AI系统。

快思与慢想:让AI学会像人一样思考的突破性研究——DualityRL团队的“思想家“模型
这项研究提出了"思想家"(Thinker)任务,一种受人类双重加工理论启发的新型AI训练方法。研究者将问答过程分解为四个阶段:快速思考(严格预算下给出初步答案)、验证(评估初步答案)、慢速思考(深入分析修正错误)和总结(提炼关键步骤)。实验表明,该方法使Qwen2.5-1.5B模型的准确率从24.9%提升至27.9%,DeepSeek-R1-Qwen-1.5B模型从45.9%提升至49.8%。显著的是,仅使用快速思考模式就能达到26.8%的准确率,且消耗更少计算资源,证明了直觉与深度推理作为互补系统的培养价值。

能力差距决定破解能力:大语言模型红队测试的能力缩放规律
这项由ELLIS研究所和马克斯·普朗克智能系统研究所的科学家进行的研究,揭示了大语言模型安全测试的根本规律:越狱攻击成功率由攻击者与目标模型间的能力差距决定。通过评估500多个攻击者-目标组合,研究团队发现:更强的模型是更好的攻击者;当目标能力超过攻击者时攻击成功率急剧下降;社会科学能力比STEM知识更能预测攻击成功。基于这些发现,研究者建立了预测模型,表明随着AI进步,人类红队测试可能逐渐失效,提示需要发展自动化安全评估方法及更全面地评估模型的说服和操纵能力。

SATORI-R1:华中科技大学研究团队通过空间定位和可验证奖励增强多模态推理能力
华中科技大学和香港中文大学研究团队提出SATORI-R1,一种通过空间定位和可验证奖励增强多模态推理的新方法。该方法将视觉问答任务分解为图像描述、区域定位和答案预测三个可验证阶段,解决了自由形式推理中注意力分散和训练收敛慢的问题。实验证明,SATORI-R1在七个视觉问答基准上一致提升性能,最高达15.7%,并展示出更聚焦的视觉注意力和更低的训练方差。
2018
01/11
14:58
分享
点赞

现在的AI已经有可能超越人类,INTUITOR系统让AI获得自我评估能力
百度2025 Q1财报深度解读:智能云表现强劲,萝卜快跑已拓展全球 李彦宏详解AI战略:AI-first战略使百度保持领先地位
重新思考数据中心架构,推进AI的规模化落地
DeepMind CEO哈萨比斯:AGI将在2030后到来,年轻人要更重视怎么学习而非学什么专业,梵高画作震撼人心是因为他的人生
大模型应该怎么用?我们大多数人都错了,微软最新研究:大模型对话次数越多,性能越差
英伟达发布Q1财报,黄仁勋:有没有美国芯片,中国AI都会高速发展
五大机器人团队谈:人形机器人的卡点和破局之道
从 0.1% 到无穷大:不断扩大的 GPT 模型如何在未知化学宇宙中变革药物发现的未来
Mistral AI 推出代理框架以争夺企业市场
对抗性 AI:金融网络安全的新前沿
Sardina 向 SUSE Enterprise Storage 用户抛出诱饵
Nvidia 超预期Q1业绩,营收同比增长 69%
无界BOUNDLESS · 数织未来AI同行|2024 TechWorld绿盟科技智慧安全大会圆满召开
保护 Active Directory 安全,Tenable 助力企业筑起安全屏障
保护 API 攻击面
您还在苦恼先修哪个漏洞吗?
加快发展新质生产力 绿盟科技与合作伙伴“做时间的朋友”
年终盘点:2023年最炙手可热的10家网络安全初创公司
向新NEW · 数智赋能新未来 | 2023TechWorld 绿盟科技智慧安全大会圆满召开
聚以致远 共筑新程 | 绿盟科技2023合作伙伴大会精彩直击
有意见 | 探索新一代金融场景的全真互联
保持热爱,奔赴下一个征程 | 绿盟科技TechWorld 2022技术嘉年华成功举行
