
“傍上”机器学习 看亚信安全运用第三代技术破解安全难题 原创
如果说人们对人工智能的到来可能会对人类本身造成威胁的担忧还为时尚早,其实用人工智能、机器学习去解决网络、信息安全问题已经成为现实。自去年以来,机器学习的概念已经逐渐被网络安全行业接受,越来越多的安全厂商推出基于AI的安全解决方案,甚至有多个初创安全公司将机器学习、人工智能作为自己的杀手锏。在国内,亚信安全是进行人工智能、机器学习用于安全方案研究最为积极的那一个,从近日召开的“C3安全峰会”将主题定为“智进·御远”可见一斑。

其实关于将人工智能用于网络安全方面一直有争议,悲观的人认为因为机器学习是寻找相似性,没有足够多的恶意访问、攻击的样本,以致无从训练,并且安全防护往往也分行业场景,机器学习难以区分应对。激进的人则认为,现在利用人工智能、机器学习是时候摆脱创建于上世纪90年代基于签名和哈希算法的陈旧方法了。
作为国内重量级的安全厂商,亚信安全对人工智能的态度更为温和,在亚信安全通用安全产品中心总经理、亚信网络安全产业技术研究院副院长童宁看来,“人工智能、机器学习毫无疑问在驱动网络安全发展。”但亚信安全不会放弃基于特征码比对的一代技术和基于行为分析的二代技术,它们的结合对于处置安全风险更为有效。
用机器学习解决安全问题的正确姿势
其实谈到机器学习,首先接触的就是它的两个主流学习方法:一是有监督学习,二是无监督学习。
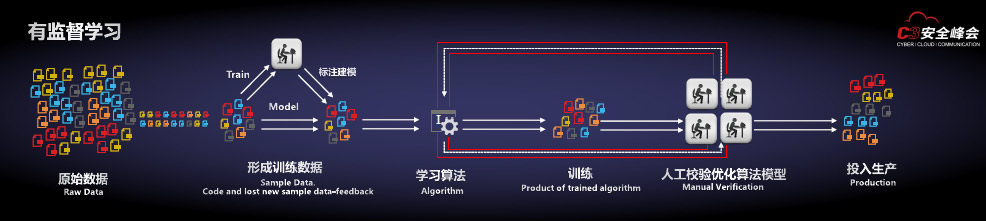
有监督学习通过已有的训练样本(即已知数据以及其对应的输出)来训练,从而得到一个最优模型,再利用这个模型将所有新的数据样本映射为相应的输出结果,对输出结果进行简单的判断从而实现分类的目的。无监督学习从无标记的训练数据中推断结论,最典型的无监督学习就是聚类分析,它可以在探索性数据分析阶段用于发现隐藏的模式或者对数据进行分组。无监督学习可以监控到一些异常的行为,还可以运用于关联分析领域。

机器学习技术用于安全的成功关键是什么?童宁总结到,一是持续性高质量的安全数据,因为网络环境一直在变化,所以机器要跟人一样,“活到老,学到老”,保证它的学习能力。二是要有网络安全领域的专家,机器要抽取哪些特征进行学习,完全由网络安全专家判断。三是要有机器学习的数据专家,包括模型、算法的建立等。
机器学习的安全应用
你也许有疑问机器学习的安全应用到底是怎样的?首先以有监督学习的角度来说,有必要先回顾下我们过去是如何识别威胁的?过去基于特征的威胁识别技术发展经历了三个阶段:
· 一维特征,黑白名单(文件,IP,域名等)
· 二维特征,字符串的匹配或者其他应用于匹配的正则表达式(IPS,DLP)
· 多维特征,组合多种特征含行为特征判定疑似对象(APT沙盒分析,网络行为监控)
当然,越多维特征进行威胁识别意味着越准确,但是它却是特别耗资源的一件事,开销太大、效率低下。

亚信安全通用安全产品中心总经理、亚信网络安全产业技术研究院副院长童宁
在有监督学习的应用里,它是一个高效的多维度的特征发现。童宁介绍了有监督学习的应用过程:首先是数据的准备;第二是进行特征的抽取,安全专家找出与威胁最相关的特征,数据专家通过数学的方法学习出体现家族性的特征组合,不同特征对家族性体现的权重不一样;第三是算法的选择,安全领域主要是采用分类算法;第四在厂商的网络进行学习;第五通过不断的学习优化算法产生N维特征组合模型;最后应用于客户的实际防御系统。
有监督学习带来了多维度的识别能力,速度效率也得到大幅度提升。虽如此但同样面临挑战:一是模型的新鲜度,因为威胁进化非常迅速,所以要保证训练数据的更新能力。二是分类识别的精度和误判管理,主要包括两个指标,正确率(Precision)与召回率(Recall)。
正确率和召回率是很多所谓的人工智能安全厂商不敢正面去谈的话题,正确率指的是抓了多少是正确的,召回率指的是漏掉了多少没有抓住。用童宁的话说,假设总共有100个文件,其中有10个恶意文件。如果人工智能从中找到5个,并且全部正确,那么正确率是100%,召回率是50%。如果人工智能从中找到 20个,包含其中10个恶意文件,那么正确率是50%,召回率是100%。也许有的厂商说我的AI安全正确率是100%,这话没有错,但却是片面的。
童宁坦言,亚信安全在实践有监督学习时,实际上一直在平衡正确率和召回率,总有一定的错误率,想要前后都做到100%目前是不可能的,现在做的是如何控制在可控的范围内。
再来看无监督学习的应用,以往基于特征的威胁治理无法满足安全的需要、传统通过建立行为基线的异常发现技术误报太多、客户对发现Unknown的未知威胁行为的需求大增。无监督学习大部分来自客户环境的数据,特征的抽取针对的是客户环境中的网络流量、业务流量和审计流量,算法基本采用聚类算法及关联分析算法,在客户的网络进行学习,模型通常设计为聚焦的简单模型避免过多误判,最终通过不断的学习优化算法产生各种基线聚类,从而定义正常行为、发现异常行为。
无监督学习通常用于反欺诈、异常发现、攻击发现、行为分析(UBA)等。但同样面临挑战,例如如何让用于建模学习的数据不受干扰、避免投毒攻击;在客户环境中进行建模学习,一般要学习几个星期甚至几个月,厂商投入成本相对较高;客户无能力持续继续运维,模型更新缓慢。
所以,用户面对机器学习安全技术的反应也不一,有的拒绝、有的相信、有的谨慎。

亚信安全在机器学习上的实践
据介绍,亚信安全基于AI的安全引擎在数据、特征识别、算法、模型等层面均有深厚积累,在亚信安全防毒墙网络版OfficeScan 12中使用了跨代整合技术,实现了AI-机器学习技术和其它防护技术融合创新。
童宁指出,在有监督学习方面,亚信安全利用其进行恶意程序及勒索病毒的防治,以及进行防治垃圾邮件等进行了实践探索。无监督学习方面,亚信安全对UBA、态势感知、以及反欺诈(信势和信盾)等产品进行了机器学习的应用。
当然,作为一家在安全领域有多年技术积累的安全厂商,亚信安全并不会依赖于人工智能、机器学习,而是博采众长,将基于特征码比对的第一代技术、基于行为分析的第二代技术和基于机器学习的第三代技术进行融合创新,保证用户高效的安全服务。
好文章,需要你的鼓励


英伟达与诺基亚联手开创AI驱动6G通信平台
英伟达和诺基亚宣布战略合作,将英伟达AI驱动的无线接入网产品集成到诺基亚RAN产品组合中,助力运营商在英伟达平台上部署AI原生5G Advanced和6G网络。双方将推出AI-RAN系统,提升网络性能和效率,为生成式AI和智能体AI应用提供无缝体验。英伟达将投资10亿美元并推出6G就绪的ARC-Pro计算平台,试验预计2026年开始。

印度理工学院突破性发现:大脑学习规律启发的全新AI图像生成技术
印度理工学院研究团队从大脑神经科学的戴尔定律出发,开发了基于几何布朗运动的全新AI图像生成技术。该方法使用乘性更新规则替代传统加性方法,使AI训练过程更符合生物学习原理,权重分布呈现对数正态特征。研究团队创建了乘性分数匹配理论框架,在标准数据集上验证了方法的有效性,为生物学启发的AI技术发展开辟了新方向。

ChatGPT不是万能的:11个不应该依赖AI的重要领域
虽然ChatGPT等AI工具正在快速改变世界,但它们并非无所不知的神谕。ChatGPT擅长"令人信服的错误",经常提供有偏见、过时或完全错误的答案。在健康诊断、心理健康、紧急安全决策、个人财务规划、机密数据处理、违法行为、学术作弊、实时信息监控、赌博预测、法律文件起草和艺术创作等11个关键领域,用户应避免完全依赖ChatGPT,而应寻求专业人士帮助。

Sony AI推出SoundReactor:让AI实时从画面生成身临其境的立体声音效
Sony AI开发出SoundReactor框架,首次实现逐帧在线视频转音频生成,无需预知未来画面即可实时生成高质量立体声音效。该技术采用因果解码器和扩散头设计,在游戏视频测试中表现出色,延迟仅26.3毫秒,为实时内容创作、游戏世界生成和互动应用开辟新可能。
2017
07/14
11:52
分享
点赞

联想集团荣获拉姆·查兰管理实践奖 以AI原生组织“破局”开源降本提效
英伟达与诺基亚联手开创AI驱动6G通信平台
智能座舱的“理想”样本背后,为什么需要一朵AI云?
ChatGPT不是万能的:11个不应该依赖AI的重要领域
核能能否成为推动全球AI发展的能源伙伴?
Blue Energy计划建设燃气转核能数据中心电厂
AI公平性:如何让人工智能真正服务社区
三星浏览器登陆Windows平台,瞄准AI发展前景
紫光股份发布 2025年三季报:做强“算力×联接” 成就强劲高增长
Oracle推出支持Apache Iceberg的多云湖仓架构
OpenAI计划IPO并完成公司重组
Equinix斥资39亿英镑收购英国赫特福德郡超大规模数据中心项目
