
深入业务流程的数据安全——炼石对CASB的中国式解读 原创
云访问安全代理(CASB ,Cloud Access Security Broker )是什么?能吃吗?怎么吃?好吃吗?
根据Gartner预测,到2018年51%的企业应用服务会托管到云上,2022年这个比例将达到85%。云端安全问题,从来都不能只寄希望于云供应商,企业注定对云端的应用程序等失去控制权了吗?
2016年的RSA大会上,企业 CIOs 探讨了“云访问安全代理”的价值,他们认为云访问安全代理模式是全面云安全的关键。
云访问安全代理(CASB ,Cloud Access Security Broker)是什么?能吃吗?怎么吃?好吃吗?
Gartner对CASB定义是:“CASB作为部署在云服务使用者和提供商之间的‘经纪人’, 能够嵌入企业安全策略,通过整合云服务发现、评级,单点登录,设备、行为识别,加密,凭证化等多种安全技术,在云上资源被连接访问的过程中并加以监控和防护。” CASB就像云服务使用者和提供商之间的“芝士夹心”,作为云端迁移的安全入口,CASB将成为企业向云上迁移的重要驱动力。
RSA大会上CIOs还热议了如何“煎炸焖煮炖”CASB,一致认同加密组件是CASB的核心功能,要确保企业外的人(包括云提供商)无法查看或访问这些数据,当数据离开企业的安全环境进入云服务提供商环境时,企业可以加密所有数据,并且只有企业有密钥。
网络安全厂商认为CASB是“很好吃”的。专注于业务应用安全领域的北京炼石网络技术有限公司,首创基于委托式安全代理技术的CASB实现模式,致力于帮助企业级用户应对业务应用云化带来的应用安全与数据安全风险,其主要产品CipherGateway业务应用安全网关及安全服务,能够提供完整满足行业合规要求的业务应用安全解决方案。

炼石创始人兼CEO 白小勇
拥有10年行业应用架构、使用模式以及业务流程等领域技术积累的炼石创始人兼CEO白小勇表示,企业要承担《网络安全法》职责,并面临国产商用密码算法升级等挑战;另一方面,十多年的信息化建设过程中,围绕企业应用的安全投入几乎没有,“应用系统内处理和流转着几乎企业所有核心数据,但又普遍缺失内生安全能力。而改造正在运行的应用系统,犹如给高速行驶中的列车更换车轮。”
对此,白小勇点明:“炼石网络的思路在于贴近应用。如果安全的逻辑没有跟业务流程结合起来,那就没有办法做到有效的数据保护。”炼石网络CMO岑义涛补充表示:“经典的CASB概念在国外成熟的SaaS市场非常吃得开,但在国内则不然,所以我们提出以适配的方式将安全能力加到应用的业务流程中。”
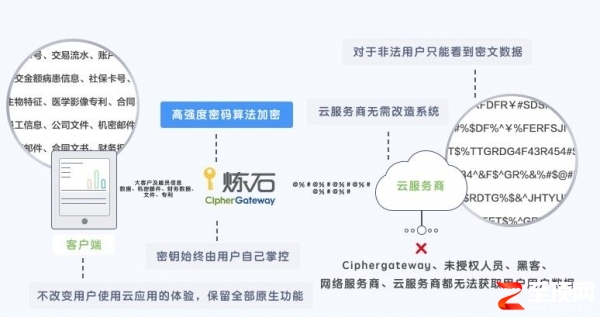
具体来说,CipherGateway业务应用安全网关,基于其核心的Broker业务处理引擎,可以在不改造用户端与服务端的情况下,通过适配方式,把数据安全乃至业务安全机制嵌入企业应用及业务流程,让应用系统获得近乎内建的安全能力。岑义涛补充:“Broker业务处理引擎不在意用户的服务端到底在哪儿,而是通过‘嫁接’的方式为数据加密。加密技术是炼石的核心技术之一。”炼石拥有专业信息安全实验室CGLab,致力于密码技术在云计算领域的工程化应用研究,以及网络安全纵深防御的工程化实践探索。
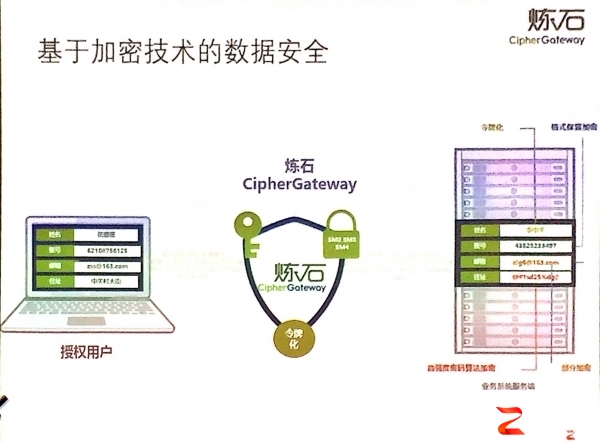
云服务使用者和提供商也饱尝了CASB的“美味”,既可以实施信息化升级以加强信息共享,同时也能掌握数据控制权。其实,炼石的CASB有两条线路,一是帮助用户在使用SaaS服务时进行安全防护;再有就是以上提到的关键应用业务保护,岑义涛举例表示:“很多典型的制造业的生产制造系统无法上云,想解决安全问题时,我们就把CASB技术模式赋到企业内网。”据悉,CipherGateway业务应用安全网关的能力可以以硬件和云服务两种模式获得,另外,对于很多在数据安全管理方面有较高要求的企业,也可以把CipherGateway作为承载和运行创新数据安全机制的一个平台。
据了解,为了进一步将适配进业务流程的数据安全以及行业化解决方案交付给用户,炼石出来着力打造Broker业务处理引擎外,还开放了炼石的适配能力,来帮助合作伙伴进一步开发利用炼石平台,使大家能够以低成本、低门槛的方式学习和使用CipherGateway来服务最终用户,让用户减少改造成本,获得更灵活、更强大的“內建”安全能力。目前,炼石已与多家主流云应用服务商达成合作,为众多企业级用户提供数据安全保护。近日,炼石更成功完成了3000万元Pre-A轮融资,领投基金十分看好炼石网络的CASB产品及服务,国科嘉和执行合伙人陈洪武总结性地表示:“炼石从源头应对业务应用、云端应用的安全与数据安全风险。开创了数据安全新模式。”
好文章,需要你的鼓励


2025-12-25
至顶AI实验室硬核评测:HP Z2 Mini G1a工作站,仅30分钟还原毛利侦探事务所
真相只有一个:在AI与创意的交汇点上,HP Z2 Mini G1a确实是一台值得推荐的灵感引擎。

德国图宾根大学团队让2D材质预测瞬间“立体化“:MatSpray技术重新定义3D物体重光照
德国图宾根大学研究团队开发了MatSpray技术,能将2D照片中的材质信息准确转换为3D模型的物理属性。该技术结合了2D扩散模型的材质识别能力和3D高斯重建技术,通过创新的神经融合器解决多视角预测不一致问题,实现了高质量的材质重建和真实的重光照效果,处理速度比现有方法提升3.5倍。

我们希望AI有多智能?世界模型可能比我们更懂世界
近年来,AI学会了写作、生成图像、创建视频甚至编写代码。随着这些能力成为主流,研究重点转向更深层问题:机器能否真正理解世界运作方式?世界模型应运而生,从1950年代概念到2024年OpenAI的Sora、2025年英伟达Cosmos等突破性应用。与语言模型基于文本预测不同,世界模型专注预测环境变化,通过学习因果关系实现推理规划。在机器人、自动驾驶等物理AI领域前景广阔,但面临计算资源需求高、数据收集困难等挑战。

纽约大学发明“大脑翻译器“:让机器人读懂人类思维,精准操控语言AI
纽约大学研究团队开发出革命性"大脑翻译器"技术,首次实现用人类大脑活动模式精确控制AI语言行为。通过MEG脑磁图技术构建大脑语言地图,提取20个关键坐标轴,训练轻量级适配器让AI按人脑思维方式工作。实验证明该方法不仅能精确引导AI生成特定类型文本,还显著提升语言自然度,在多个AI模型中表现出良好通用性,为人机交互和AI可控性研究开辟全新路径。
2017
09/20
11:31
分享
点赞

最新文章
至顶AI实验室硬核评测:HP Z2 Mini G1a工作站,仅30分钟还原毛利侦探事务所
冷板式液冷CDU系统
开箱 NVIDIA DGX Spark: 把一千万亿次算力,“塞进”ipad mini大小的盒子里
我们希望AI有多智能?世界模型可能比我们更懂世界
首席信息官角色将在2026年扩展的四种方式
Waymo正在测试Gemini在无人驾驶出租车中的车载AI助手功能
数据中心从幕后走向台前的转折之年
意大利要求Meta暂停禁止竞争对手AI聊天机器人使用WhatsApp的政策
让老旧Windows和macOS系统延续生命力
微软计划到2030年用Rust语言替换所有C和C++代码
2026年创客工具迎来重大升级,这些新技术值得期待
2025年十大网络故事盘点
相关文章

邮件订阅
白皮书