
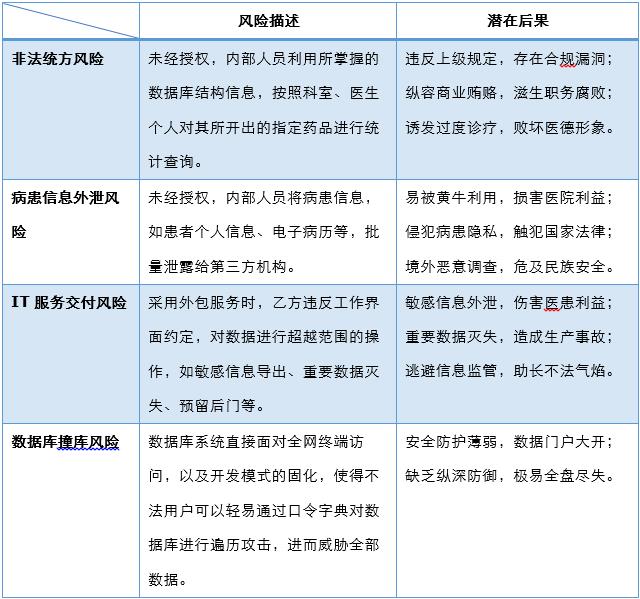
瞄准医疗数据安全四大风险 东软DBA如何绝地阻击 原创
作为与人民生活福利密切相关的保障性设施,医疗行业单位,尤其是大中型医院的信息化建设始终领先于社会同期平均水平,各业务环节几乎已全部纳入到IT信息链条中,并逐步呈现出自成体系的信息技术范畴。与之相应的,医疗单位也面临着其行业独有的数据安全风险。
为解决以上问题,东软推出了以数据库审计系统(DBA)为依托的NetEye数据安全平台,面向医疗行业数据安全需求,提供成熟、可靠的整体解决方案,并在各个领域均表现出鲜明的优势特点。
一、防范非法统方
通过内置的专业防统方功能,东软 DBA能够实时检测针对HIS系统的非法统方行为,保护医疗单位合法权益,提高通过行业规章要求、等级保护等标准规范的能力。
(一)准确度极佳。东软DBA了解HIS数据库结构,具备准确的统方模型定义,具备制订出业内精确度领先的统方策略的能力,是东软DBA在防统方领域无与伦比的先天优势。

(二)误报率低。东软在医疗信息化领域审核二十余年,了解客户需求,熟悉各医疗流程的运维操作特点,如药库/药房管理、药品字典维护、药品/非药统计、就诊信息查询等,能够准确甄别误判环节,将误报率控制在可接受范围内。
(三)漏报率优异。东软DBA不仅仅审计对指定数据对象的访问,而且还将通过其它技术手段进行辅助检测,防范个别内部人员通过数据库内部机制进行间接统方,如数据转存、设立视图、调用存储过程/函数等,截断逃避监管的隐蔽通道,实现良好的审计覆盖面。
(四)层次化的检测阶梯。东软DBA的防统方策略,不是简单几条检测策略配置的罗列,而是在充分理解HIS数据库结构和业务特征的基础上,制订出的层次化的检测策略阶梯,并根据命中率、可疑度、防漏审/漏报、防误报、执行效率等因素综合权衡,严谨选择每条检测规则的检测粒度以及所处的阶梯位置,从而使DBA防统方实现良好的检测性能和效果。
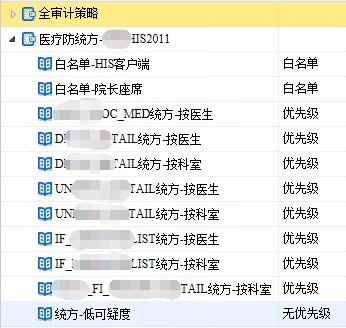
(五)开箱即用。为便于客户对DBA防统方功能的高效运用,东软DBA将防统方功能单独封装为策略包和报表模块,每个策略包均针对特定品牌、特定版本的HIS系统而专门打造,用户可通过报表模块自动生成指定类型的防统方合规报表,降低部署难度,提高审计监管力度。
二、保护病患信息
病患信息是医疗单位重点保护的数据资产,此类信息广泛分布在HIS、EMR、CPR等系统的数据库中。一方面,病患信息数据需要面向正常业务系统提供全面访问服务;另一方面,又需要向特定的临时请求开放有限的访问权限,如医学科研课题研究、临床案例样本调查等。
东软DBA数据安全平台能够提供完善的敏感数据保护机制,满足客户的多种需求。
(一)基于数十种条件来严格描述各类用途的业务访问请求,为后续敏感数据保护提供访问源定义。
(二)按照可操作记录数量来约束数据扩散速度。
(三)按照字段类别来控制可访问数据范围。
(四)在可访问范围内,对其中的敏感数据进行事前静态、实时动态脱敏处理和事前静态加密处理。
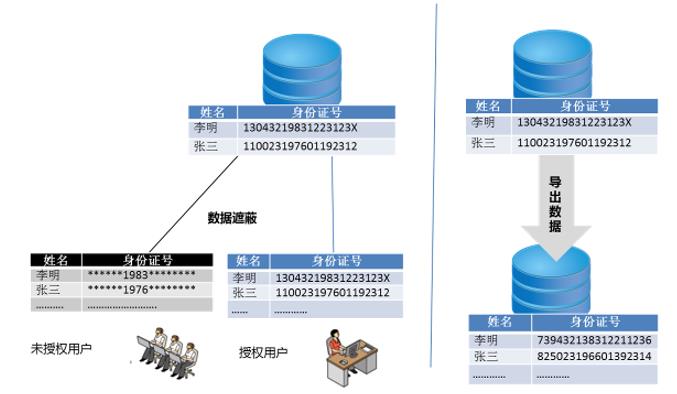
东软DBA数据安全平台,妥善满足了医疗行业敏感数据的弹性保护需求,把以往简单粗暴的“允许、禁止”二元制策略,进一步优化为“允许、禁止、允许但需少量、允许但需脱敏”多元制保护体系。
三、监督IT服务
通常,在信息化建设过程中,医疗机构与IT服务商将在约定的工作界面内按照合同要求交付工作,保质、保量。然而,在实际操作过程中,难免出现分工界面不清晰或使用混乱、交付成果不明确等情况,极易引发一系列的安全隐患,如数据泄露、后门预留等。针对此风险,东软DBA数据安全平台可将IT服务工作限定在一个可控、可审计的范围内。
(一)提供数据访问控制机制,约束IT服务人员的数据访问范围。
(二)提供数据加密和脱敏机制,防止敏感数据泄露。
(三)采用数据审计手段,监督对核心数据资产的全部访问。
(四)采用运维审计手段,监控对核心系统的维护操作(NABH运维审计)。
(五)设置审计报警策略,对高可疑度的访问、操作进行实时报警,及时通知安全管理员排查可疑行为。
东软DBA数据安全平台能够为医疗单位的信息化建设提供可靠的沙盒环境,监督、约束IT服务有序交付,避免对现网系统造成安全威胁。

四、增加纵深防御
从安全层面上来看,医疗单位信息系统是近似平坦的结构,几乎所有的桌面系统都可以访问所有的服务器资源,无论是应用业务服务器还是数据服务器,尤其是在应用层<->数据层之间,几乎是全连通的。这对安全防护非常不利。
东软DBA数据安全平台可方便、高效地增加医疗单位信息系统的防御纵深。
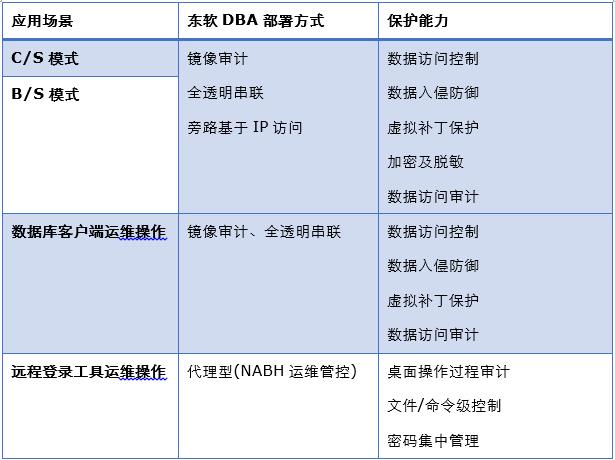
东软DBA数据安全平台,兼具数据库审计、数据库防火墙、数据库加密和数据库评估扫描模块功能,并内置SOX、等级保护、防统方、PCI等报表模板,可有力促进医疗单位进行内部监管强化、安全评测申报以及切实提高数据安全水平等工作。
好文章,需要你的鼓励



让AI看图功能瘦身90%:希腊塞萨洛尼基大学发现图像修复“中奖彩票“神经网络
希腊塞萨洛尼基大学研究团队开发出MIR-L算法,通过"彩票假说"发现大型图像修复网络中的关键子网络。该算法采用迭代剪枝策略,将网络参数减少90%的同时保持甚至提升修复性能。MIR-L能同时处理去雨、去雾、降噪等多种图片问题,为资源受限设备的实时图像处理提供了高效解决方案,具有重要的实用价值和环保意义。

人工智能使用大揭秘:OpenRouter公司百万亿规模数据分析报告
这项由OpenRouter公司团队和Andreessen Horowitz(a16z)投资机构联合开展的研究,于2025年12月发表。

卡内基梅隆大学提出DistCA:让AI训练告别“木桶效应“的神奇技术
卡内基梅隆大学团队提出DistCA技术,通过分离AI模型中的注意力计算解决长文本训练负载不平衡问题。该技术将计算密集的注意力任务独立调度到专门服务器,配合乒乓执行机制隐藏通信开销,在512个GPU的大规模实验中实现35%的训练加速,为高效长文本AI模型训练提供了新方案。
2017
08/03
17:23
分享
点赞

NVIDIA Nemotron 3 系列开放模型: 击穿AI“工程墙”开启“Agentic AI”的“Linux时刻”
W.AWARDS金网奖2026未来商业计划领航秀峰会收官
人工智能使用大揭秘:OpenRouter公司百万亿规模数据分析报告
智能化与全球化并进,IBM中国下一个40年思考
通用汽车推出原生Apple Music应用并支持空间音频
GMV推进卫星导航技术助力自动驾驶运输与物流发展
英伟达考虑增产H200芯片满足中国市场激增需求
IBM推出开源智能体CUGA 任务完成率超五成
OpenAI支持的生物技术公司Chai Discovery获1.3亿美元B轮融资
八问智能时代:西云数据的八个答案
塑造2026年的八大智能手机趋势
AI架构师荣获《时代》杂志年度人物称号
